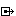
More ...
編集履歴:差分
記録開始と2015/10/09 15:16:44 JST間の正規表現の変更箇所
- + 追加された行
- - 削除された行
+ HSP製の正規表現エンジンです.~% + 対応する記号は,'*','|','(',')'のみです.(他の文法の追加も容易であると思います)~% + 改良求みます. + + 別途,vain0さんのabdataモジュールが必要です.~% + [https://github.com/vain0/abdata] + + ** 実行結果 + + [[$$img http://cdn.devlion.net/regexp_ss.png]] + + ** regexp.hsp + {{{ + #include "abdata/abdata/all.as" + + #enum global ND_Union = 0 + #enum global ND_Star + #enum global ND_Char + #enum global ND_Concat + #enum global ND_Empty + + #enum global OP_Char = 0 + #enum global OP_Match + #enum global OP_Jump + #enum global OP_Split + + #enum global CD_Opecode = 0 + #enum global CD_Operand1 + #enum global CD_Operand2 + + /************************* + * VM + * 実際にテストを行う仮想マシン + * Compilerが吐くlistを実行する + *************************/ + + #module VM pc, sp, mem, text + + #modinit int _mem, str _text + pc = 0 // 実行中のmemのインデックス + sp = 0 // 判定中のtextのインデックス + mem = _mem // コンパイルされた正規表現 + text = _text // 対象の文字列 + return + + // textに対して判定を行う + #modcfunc start local tmp_pc, local tmp_sp, local ins, local result + + result = 0 // 0ならマッチ失敗、1ならマッチ成功 + + // memを0からOP_Matchが表れるまで実行する + repeat + + ins = list_get(mem, pc) // 実行する命令 + + // 命令ごとに処理を分ける + switch(list_get(ins, CD_Opecode)) + + // PCをオペランド1に置き換える + case OP_Jump + pc = list_get(ins, CD_Operand1) - 1 + swbreak + + // PCをオペランド1として新しいスレッドを作成 + // その後、PCをオペランド2として続行 + case OP_Split + tmp_pc = pc + tmp_sp = sp + pc = list_get(ins, CD_Operand1) + if (start(thismod)) : result = 1: break + + sp = tmp_sp + pc = list_get(ins, CD_Operand2) - 1 + swbreak + + // textのSP番目の文字が、オペランド1と等しいか判定 + // 等しくなければスレッドを終了 + case OP_Char + if (peek(text, sp) == list_get(ins, CD_Operand1)) { + sp++ + } else { + result = 0 : break + } + swbreak + + // マッチ成功 + case OP_Match + result = 1 : break + swbreak + swend + + pc++ // 次の実行のために、PCを更新する + + loop + return result + + #modfunc set_pc int _pc + pc = _pc + return + + #modcfunc get_pc + return pc + + #modfunc set_sp int _sp + sp = _sp + return + + #modcfunc get_sp + return sp + + #global + + /********************************* + * Parser + * 正規表現から構文木を作成する + *********************************/ + + #module Parser pattern, it + + #modinit str _pattern + pattern = _pattern // 正規表現 + it = 0 // 現在処理している文字のインデックス + return + + // パースを行う + // 返り値としてtnode(tnx)が返る + #modcfunc parse local result + + result = parse_exp@Parser(thismod) + + return result + + // 正規表現全体をパース + #modcfunc local parse_exp local result + + result = parse_subexp@Parser(thismod) + + // もし、正規表現の最後まで到達しなかった場合、構文エラー + if (strlen(pattern) != it) { + dialog "Could not reach EOF" + return result + } + + return result + + // '|'を含む正規表現をパース + #modcfunc local parse_subexp local result, local node1, local node2 + result = parse_subseq@Parser(thismod) + + // '|'であるかどうか + if (peek(pattern, it) == $7c) { + // node1は'|'の左側 + // node2は'|'の右側 + + it++ + node1 = result + node2 = parse_subexp@Parser(thismod) + + tnode_new result, ND_Union, list_make() + + tnx_addChd result, node1 + tnx_addChd result, node2 + } + + return result + + // 文字オブジェクトをパース(通常の文字または、'('~')'で表される集合) + #modcfunc local parse_factor local result + + // '('であるかどうか + if (peek(pattern, it) == $28) { + it++ + result = parse_subexp@Parser(thismod) + } else { + // 通常の文字 + tnode_new result, peek(pattern, it), list_make() + } + + it++ + + return result + + // 連接文字をパース + #modcfunc local parse_seq local result, local tmp + tmp = peek(pattern, it) + + // '('または、記号ではない通常の文字 + if (tmp == $28 || (tmp != $7c && tmp != $29 && tmp != $2a && tmp != $00)) { + return parse_subseq@Parser(thismod) + } + + tnode_new result, ND_Empty, list_make() + return result + + // '*'または文字、'*'または文字と文字の連接をパース + #modcfunc local parse_subseq local result, local node1, local node2, local tmp + + result = parse_star@Parser(thismod) + + tmp = peek(pattern, it) + + // '('または、記号ではない通常の文字 + if (tmp == $28 || (tmp != $7c && tmp != $29 && tmp != $2a && tmp != $00)) { + node1 = result + node2 = parse_subseq@Parser(thismod) + tnode_new result, ND_Concat, list_make() + tnx_addChd result, node1 + tnx_addChd result, node2 + } + + return result + + // '*'をパース + #modcfunc local parse_star local result, local tmp + result = parse_factor@Parser(thismod) + + // '*'であるかどうか + if (peek(pattern, it) == $2a) { + tmp = result + tnode_new result, ND_Star, list_make() + tnx_addChd result, tmp + + it++ + } + return result + + #global + + + /************************* + * Compiler + * 構文木からVM用のバイトコードを生成する + *************************/ + + #module Compiler pc, ast + + #modinit int _ast + pc = 0 // 現在コンパイル中のインデックス + ast = _ast // 構文木 + return + + // コンパイルを行う + // 返り値としてバイトコードのlistが返る + #modcfunc compile local result, local tmp + + list_new result + + pc = 0 + + // コンパイル + compile_node@Compiler thismod, ast, result + + // 最後にOP_Matchを追加する + list_new tmp + list_add tmp, OP_Match + list_add tmp, 0 + list_add tmp, 0 + + list_add result, tmp + + return result + + // ノード単位のコンパイル + // 再帰的に実行される + // 変換先のバイトコードに関しては以下を参照 + // http://qiita.com/yyu/items/84b1a00459408d1a7321#%E6%AD%A3%E8%A6%8F%E8%A1%A8%E7%8F%BE%E3%81%8B%E3%82%89%E3%83%90%E3%82%A4%E3%83%88%E3%82%B3%E3%83%BC%E3%83%89%E3%81%B8%E3%81%AE%E5%A4%89%E6%8F%9B + #modfunc local compile_node int node, int code, local tmp, local tmp1, local tmp2 + + switch(tnode_get(node)) + case ND_Concat // 連接 + + // 二つの要素をそれぞれ順にコンパイルする + compile_node@Compiler thismod, tnxChd(node, 0), code + compile_node@Compiler thismod, tnxChd(node, 1), code + + swbreak + + case ND_Star // '*' + + list_new tmp + list_add tmp, OP_Split + list_add tmp, pc + 1 + list_add tmp, 0 + + list_add code, tmp + + tmp1 = pc + + pc++ + + compile_node@Compiler thismod, tnxChd(node, 0), code + + list_new tmp + list_add tmp, OP_Jump + list_add tmp, tmp1 + list_add tmp, 0 + + list_add code, tmp + + pc++ + + list_ref(list_get(code, tmp1), CD_Operand2) = pc + + swbreak + + case ND_Union // '|' + list_new tmp + list_add tmp, OP_Split + list_add tmp, pc + 1 + list_add tmp, 0 + + list_add code, tmp + + tmp1 = pc + + pc++ + + compile_node@Compiler thismod, tnxChd(node, 0), code + + list_new tmp + list_add tmp, OP_Jump + list_add tmp, 0 + list_add tmp, 0 + + list_add code, tmp + + tmp2 = pc + + pc++ + + compile_node@Compiler thismod, tnxChd(node, 1), code + + list_ref(list_get(code, tmp1), CD_Operand2) = tmp2 + 1 + list_ref(list_get(code, tmp2), CD_Operand1) = pc + + swbreak + + case ND_Empty + + swbreak + + default // ND_Char + list_new tmp + list_add tmp, OP_Char + list_add tmp, tnode_get(node) + list_add tmp, 0 + + list_add code, tmp + + pc++ + swbreak + swend + + return + + #global + + + /************************* + * Regexp + * 正規表現を管理する + *************************/ + + #module Regexp code + + #modinit str _pattern, local par, local com, local ast + // 正規表現をパース + newmod par, Parser, _pattern + ast = parse(par) + delmod par + + // 構文木をコンパイル + newmod com, Compiler, ast + code = compile(com) + delmod com + + // デバッグ用 + // バイトコードの様子が見れます + /*repeat list_size(code) + buf = strf("%d: ", cnt) + ins = list_get(code, cnt) + op1 = list_get(ins, CD_Operand1) + op2 = list_get(ins, CD_Operand2) + tmp = " " + switch list_get(list_get(code, cnt), CD_Opecode) + case OP_Split + buf += strf("SPLIT %d, %d", op1, op2) + swbreak + case OP_Jump + buf += strf("JUMP %d", op1) + swbreak + case OP_Char + poke tmp, 0, op1 + buf += strf("CHAR %s", tmp) + swbreak + case OP_Match + buf += "MATCH" + swbreak + swend + + logmes buf + loop*/ + + tnode_delete ast + return + + #modterm + IterateBegin code, list + list_delete it + IterateEnd + + list_delete code + return + + // 判定を行う + // マッチに成功すれば1、失敗すれば0が返る + #modcfunc match str _text, local machine, local result + newmod machine, VM, code, _text + result = start(machine) + delmod machine + return result + + #global + + + /*********************************** + * サンプル + ***********************************/ + + pattern = "(Objective-)*C(++|#)*" + lang = "B", "C", "C++", "C#", "Objective-C", "D" + + newmod clike, Regexp, pattern + + mes "Pattern:" + pattern + mes + + repeat length(lang) + if (match(clike, lang(cnt)) == 1) { + color 0, 128, 0 + mes strf("%s is C-like!", lang(cnt)) + } else { + color 128, 0, 0 + mes strf("%s", lang(cnt)) + } + loop + + delmod clike + }}} + + *** 参考 + [http://qiita.com/yyu/items/84b1a00459408d1a7321]~% + [http://codezine.jp/article/corner/237]